Applications and Limits of
Machine Learning
for
Language Documentation Resources
(University of Cologne)
Linguistic diversity, minority languages and digital research infrastructures
Hamburg, September 20-21 2018
Background:
experience from work with machine learning and audio data from language documentation in the KA³ project ... from a field linguist’s and archivist’s perspective.
The linguist’s problem:
Data preparation is time consuming and often the bottle neck that prevents the production of data sets large enough for many types of analysis.
- identify speech
- associate with speaker
- transcribe
- translate
- annotate
Speech technology:
- automatic annotation ✘
- automatic translation ✘
- automatic transcription ✘
- speaker diarization ✔︎
- speech/non-speech detection ✘
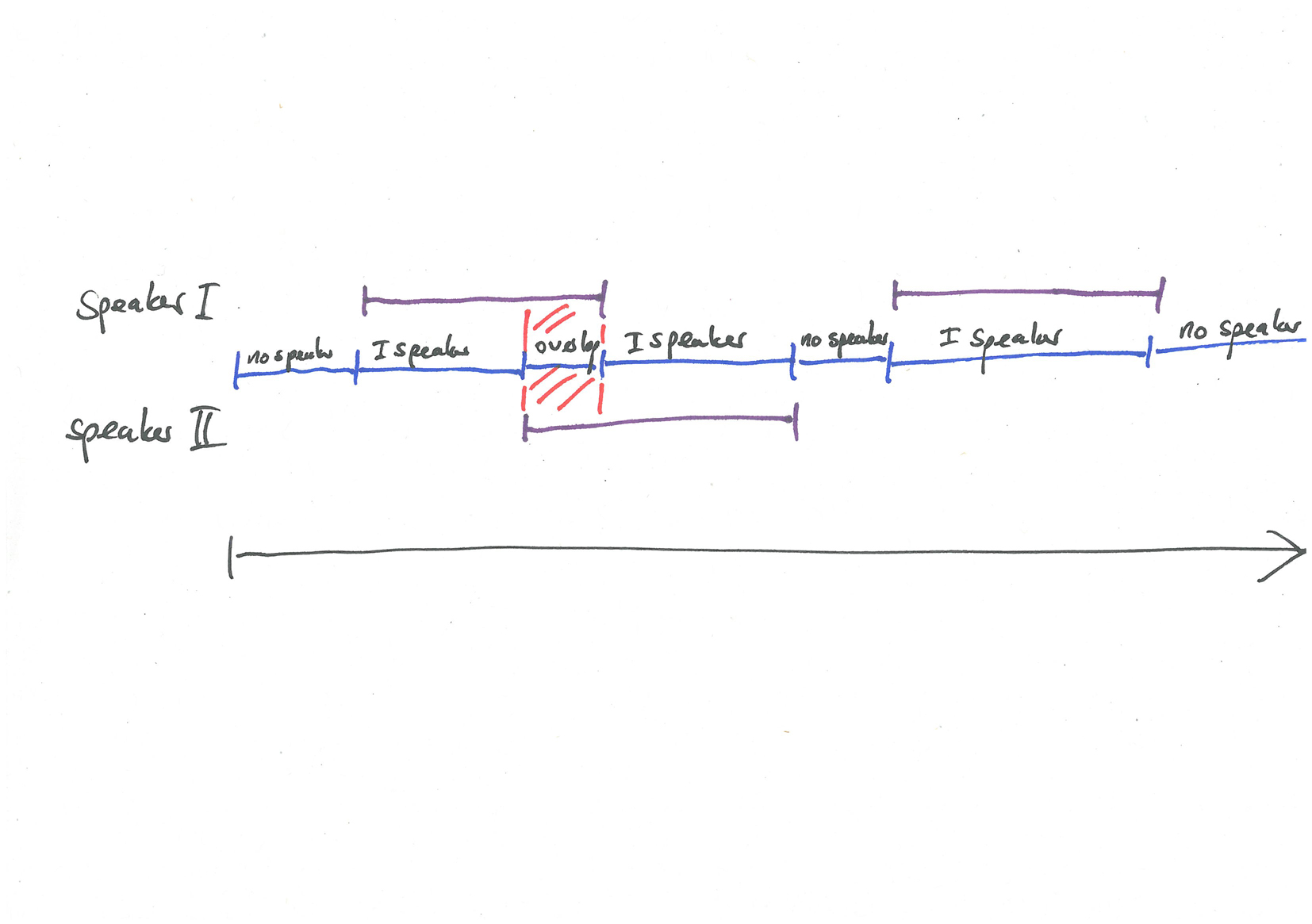
Speaker diarization:
- language independent ✔︎
- sufficient amount of data ?
- sufficiently (and consistently) annotated data ?
- interesting problem ✔︎
- solvable problem ?
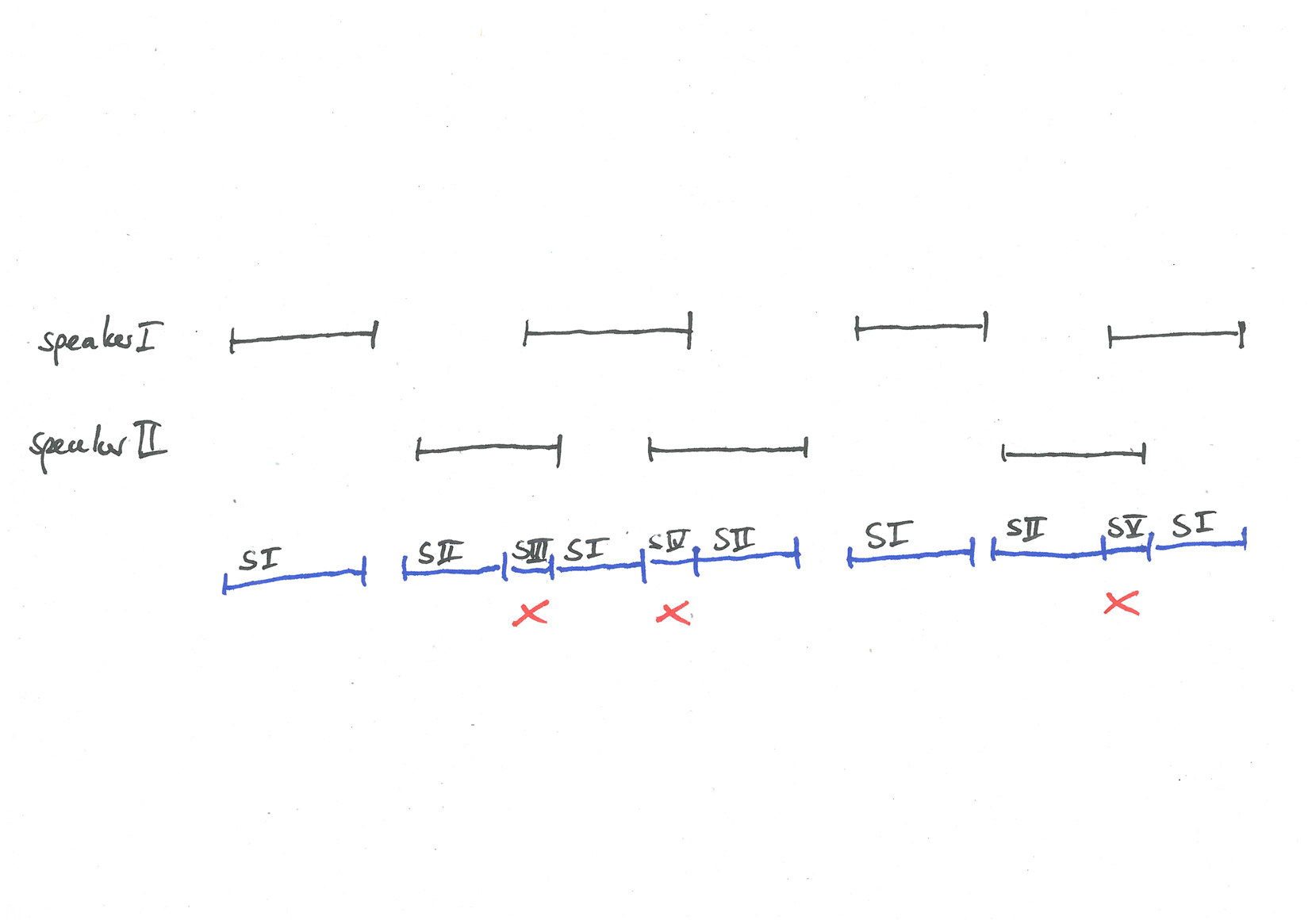
Overlap
- overlap is a major issue for speaker recognition
- creates spurious speakers
- interactionally interesting
- natural overlap tends to be extremely short
- previous speech technology research has worked with artificially created, unrealistically long overlap
Machine learning
(aka artificial intelligence)
Sorry...
Machine learning
(aka artificial intelligence)
| regression | vs | classification |
| supervised | vs | unsupervised |
KA³ approach:
- lowlevel acoustic features (64-dimensional log₁₀-Mel-Filterbank Coefficients extracted every 10 ms over a window of 32 ms)
- Supervised learning (Every frame of the extracted acoustic features classified into 3 classes: 0 speakers, 1 speaker, more than 1 speakers. Ground truth taken from annotations; i.e. ELAN files.)
- Deep Convolutional Neural Network based classifier (based on VGG-net, 572,035 trainable parameters; 3 convolutional blocks, 3 dense blocks, softmax)
- some post-processing (temporal smoothing)
P(REC)) 76.06 ( 88.77) 92.37 ( 82.57) 4.07 ( 9.34) | Viterbi : P(REC)) 82.30 ( 90.65) 93.70 ( 88.29) 5.19 ( 5.93) | interview_IP_Mika_swapped P(REC)) 68.40 ( 87.55) 91.27 ( 78.92) 4.36 ( 3.83) | Viterbi : P(REC)) 73.47 ( 88.81) 92.19 ( 83.92) 6.99 ( 2.38) | interview_IP_Obok_I P(REC)) 68.46 ( 87.52) 91.27 ( 78.99) 4.59 ( 4.01) | Viterbi : P(REC)) 73.48 ( 88.68) 92.12 ( 83.94) 6.83 ( 2.32) | interview_IP_Obok_I_swapped P(REC)) 47.20 ( 87.10) 94.21 ( 70.43) 2.50 ( 4.09) | Viterbi : P(REC)) 52.24 ( 89.51) 95.30 ( 75.74) 3.99 ( 2.97) | interview_KW_Ware P(REC)) 47.22 ( 87.12) 94.21 ( 70.45) 2.50 ( 4.09) | Viterbi : P(REC)) 52.33 ( 89.55) 95.32 ( 75.82) 4.07 ( 2.97) | interview_KW_Ware_swapped FINAL - RAW PRECISION RECALL [ 52.23 24.30 16.85] [ 63.84 35.70 0.47] [ 44.94 70.94 73.11] [ 34.08 64.66 1.26] [ 2.83 4.76 10.05] [ 32.21 65.19 2.59] FINAL - VITERBI PRECISION RECALL [ 54.70 23.10 16.35] [ 64.52 35.28 0.20] [ 42.67 72.00 71.33] [ 31.23 68.22 0.55] [ 2.63 4.90 12.32] [ 28.90 69.67 1.44] \TESTING ENDED 2018-04-02 14:08:40.483056
Issues (machine learning):
- First time working with realistic (not artificially created) overlap
- Results are a substantial improvement compared to state of the art
- Amount of data not sufficient
- Imbalanced phenomenon (Overlap differs widely 0.4-12% in dialogue, but on average makes up less than 5% of the data.)
- Making the neural network larger won’t help (overfitting)
Issues (data):
- For (current) ML, we need much more annotated data.
- Language specific ML tasks probably unrealistic for underresourced languages.
- Recording quality matters
- Recording format matters (to a degree)
- Consistency of annotations matters
Issues (metadata and discoverability):
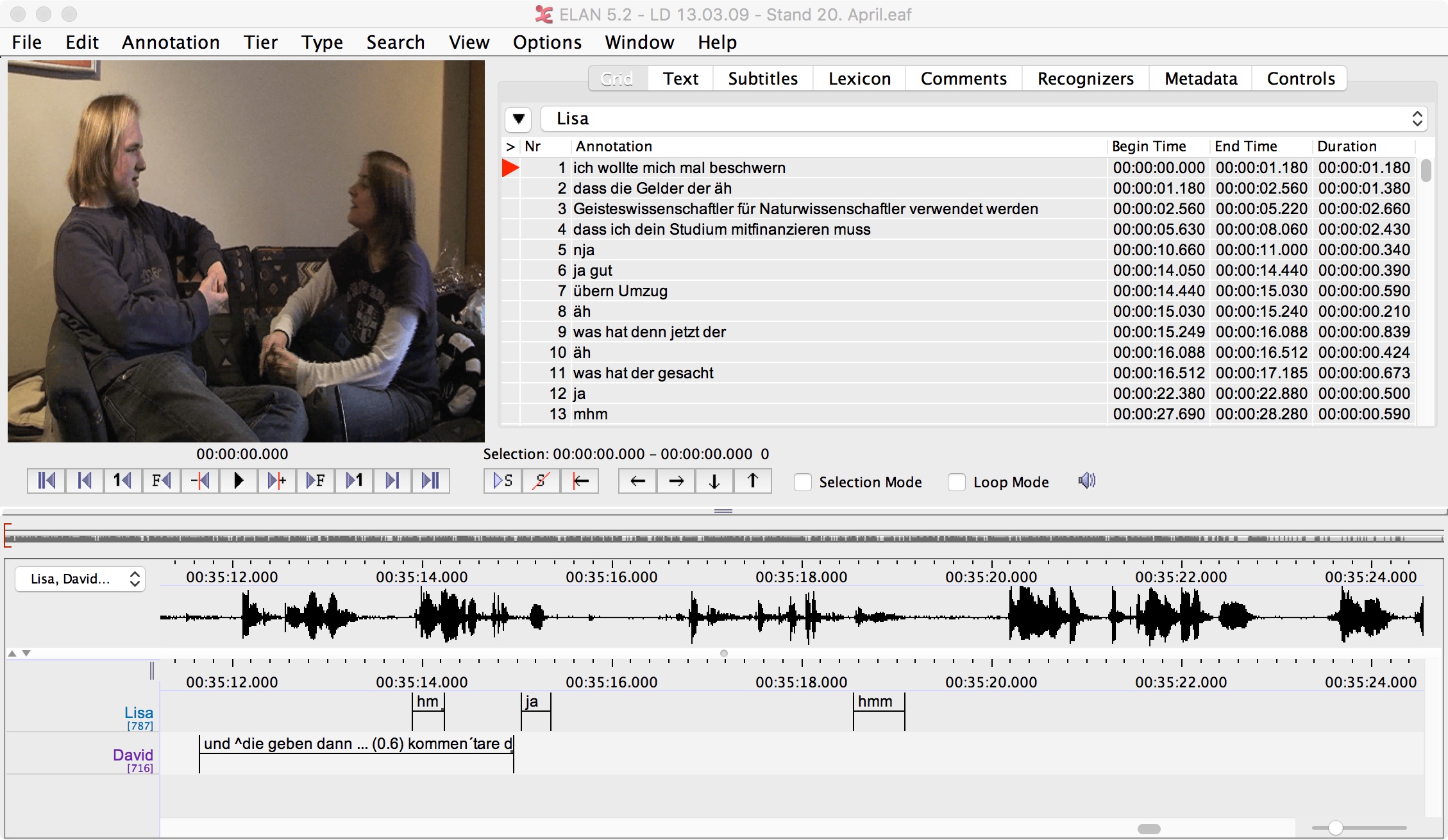
- It was unrealistic to use data from language archives. (discovery and retrieval issues)
- I had to talk to individual researcher to identify candidate recordings.
- I had to listen to the recordings, watch the video, and scroll to the annotation files.
- We had to use error-prone heuristics to identify relevant tiers.
- This does not scale well.
Issues (metadata and discoverability):
- It was unrealistic to use data from language archives. (discovery and retrieval issues)
- I had to talk to individual researcher to identify candidate recordings.
- I had to listen to the recordings, watch the video, and scroll to the annotation files.
- We had to use error-prone heuristics to identify relevant tiers.
- This does not scale well.
Issues (metadata and discoverability):
- It was unrealistic to use data from language archives. (discovery and retrieval issues)
- I had to talk to individual researcher for candidate recordings.
- I had to listen to the recordings, watch the video, and scroll to the annotation files.
- We had to use error-prone heuristics to identify relevant tiers.
- This does not scale well.
- It is virtually impossible to identify suitable data sets for this task.
Possible improvements
- Better data: Quality standards for annotated corpora
- Better discoverability: Improved metadata for identifying relevant data sets
- Better landscape: Funding for data collection and credits for data publication
General remarks:
- Virtually no linguistic or phonetic knowledge went into the ML aspect of the project.
- The neural network was developed for visual ML.
- Linguistic data collection and preparation is valuable.
- Metadata are valuable.
- Repositories are (or would be) valuable.
“Every time I fire a linguist, the performance of the speech recognizer goes up.”
Frederick Jelinek
Credits:
Abdullah (IAIS), Michael Gref (IAIS), Joachim Köhler (IAIS), Nikolaus Himmelmann (IfL), Christoph Stollwerk (RRZK).
References
Abdullah 2017. “Detecting double-talk (overlapping speech) in conversations using deep learning.” MA Thesis.
http://publica.fraunhofer.de/dokumente/N-477004.html
Thank you!
f.rau@uni-koeln.de